


使用 KNIME Python 集成(实验室)在 KNIME 和 Python 之间进行闪电般的快速数据传输
使用KNIME Python集成在KNIME和Python之间进行闪电般的快速数据传输。
如果我们告诉您近期引入的Python 脚本 (Labs)节点使 Python 在 KNIME 中的速度与在其他地方一样快,那会怎样?没错,KNIME 将表传输到 Python 节点时没有延迟。
在这篇文章中,我们讨论了 Python Script (Labs) 节点,该节点目前作为KNIME Python Integration (Labs)扩展的一部分提供。
KNIME Python 集成链接编码器和非编码器
近年来,低代码工具使广泛的用户可以访问数据科学。数据科学已成为行业不可或缺的一部分,各个领域的人们都在拥抱它,从人力资源经理到会计师、化学工程师等等。用户更喜欢与各自领域中现有技术或编程语言兼容的软件。
KNIME 分析平台就是这样一种低代码软件,因为它可以与别的工具、软件或编程语言集成,因此在广泛的行业中使用。
每个组织都由编码员和非编码员组成。编码人员更喜欢编程语言来完成日常数据科学任务,而非编码人员更喜欢低代码平台。KNIME Python Integration 已经被证明是这两个群体之间的纽带。它允许 KNIME 用户在 KNIME 分析平台内运行 Python 脚本,还允许 Python 用户以KNIME 组件的形式打包他们的自定义库,以便他们可以地运行它们。
通过KNIME Python 集成 (Labs)扩展,可以使用新的 API 来访问数据。在本文中,我将查看一些用例以了解性能的提升,然后展示如何使用批处理来避免执行期间的本地内存问题。
了解性能提升 ——用例 1
对于这个例子,我们有著名的 2008 年航空公司数据集,其中包含大约 200 万行,每行表示指定日期的单个航班的信息,以及它是否被转移、取消或延误。作为一名数据科学家,我们打算对这个数据集应用一些数据转换,以便我们可以为下游任务准备这些数据。我们决定计算“出发延迟”列与平均值的偏差。尽管 KNIME 为数据转换提供了各种本地节点,但我们对使用 python 包应用转换很感兴趣。为此,我们将使用 Python Script 节点以及近期发布的 Python Script (Labs) 节点来比较它们的性能。用于此任务的工作流程如图 2 所示。
为了确保我们获得快的性能,我们将切换到KNIME Columnar Table 后端 扩展。这可以通过右键单击 KNIME Explorer 中的工作流名称,然后单击“配置”选项来配置。选择 Table Backend 作为“Columnar Backend”,如图 1 所示。
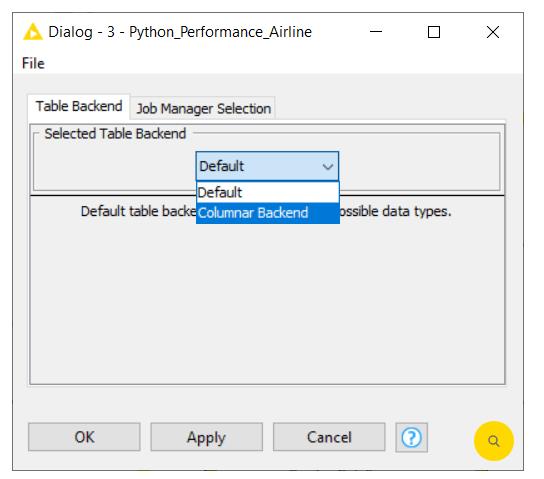
图 1:配置工作流以使用列式后端。
200 万行数据操作性能提升 50 倍
从图 2 所示的影片中可以看出,从 Python 访问 KNIME 表并在 200 万行上应用数据操作需 15 秒 ——使用带有 Pyarrow 或 Pandas 的 Python Script (Labs) 节点(绿色注释框) . 旧的 Python Script 节点需要超过 5 分钟。这几乎是 50 倍的改进。Apache Arrow后端很大地减少了 KNIME 和 Python 之间的数据传输开销。
 图 2:使用 Python 性能工作流程比较新旧 API 的性能。
图 2:使用 Python 性能工作流程比较新旧 API 的性能。
请注意,即使我们为工作流使用默认后端,与 Python 脚本节点相比,Python 脚本 (Labs) 节点对于 KNIME 和 Python 之间的数据传输操作仍然更快。但我们建议切换到“Columnar Backend”,这可以通过 Python Script (Labs) 节点提供很好性能。
如何使用新 API?
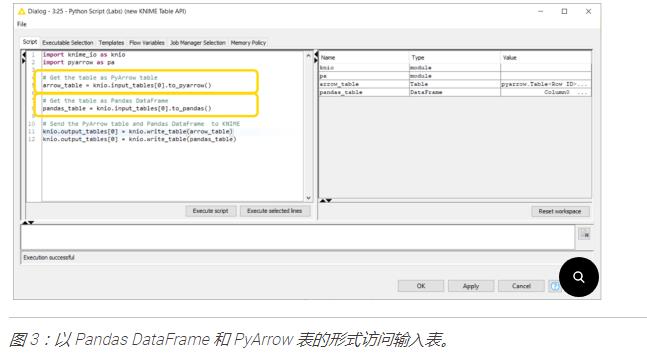
可通过knime_io模块获得的新 API 提供了一种访问进入 Python 脚本 (Labs) 节点的数据的新方法。当您将节点拖到 KNIME 分析平台时,默认情况下会将 knime_io 导入到脚本中。进入节点的数据可以作为 Pandas DataFrame 或 PyArrow Table 访问。这很酷,因为当我们想要执行一些数据操作时,我们可以将输入数据作为 PyArrow 表访问,如果我们想在数据上运行机器学习模型,也可以作为 Pandas DataFrame 访问数据。图 3 显示了用于访问进入 Python 脚本(实验室)节点的数据的代码片段。
展示批处理 ——用例 2
在这个例子中,我们想要在 2008 Airline Delay 数据集上训练一个分类模型来预测给定的航班是否会延误。这个训练有素的模型也将用于预测即将到来的航班的状态。
我们使用图 4 所示的工作流程来完成这项任务。在左侧,我们导入两年一次的数据文件并附加它们。然后处理此附加数据并将其提供给分区节点以分为训练集和测试集。由于集合很大,我们只使用 10% 的数据进行训练,因为这足以让模型学习;剩下的 90% 作为测试集。
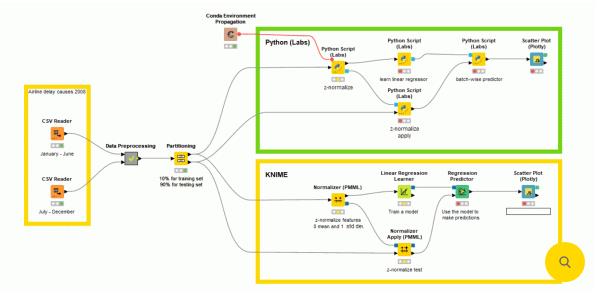
图 4:使用 Python 脚本(实验室)和原生 KNIME 节点训练分类模型的延迟预测工作流程。
我们决定对这个分类任务使用逻辑回归。同样,我们使用两个不同的分支执行此任务,这将帮助我分析性能。在一个分支(绿色注释框)中,我们使用 Python 脚本(实验室)节点来训练模型,并使用批处理来预测庞大的测试集(大约一百万行)。这种批处理帮助我们批量访问这百万行,即使 RAM 量较小。在第二个分支(黄色注释框)中,我们使用原生 KNIME 节点。
正如您在上面的图 4 中的影片中看到的那样,Python 脚本 (Labs) 几乎达到了原生 KNIME 节点的性能。
什么是 Python 脚本(实验室)节点中的批处理?
Python Script (Labs) 节点支持批处理:这是一个令人兴奋的新功能,它允许我们使用 knime_io 模块批量处理数据。以前输入数据的大小受机器上可用 RAM 量的限制,而 Python Script (Labs) 节点可以通过批量访问数据来处理任意大量数据,如图 5 所示。
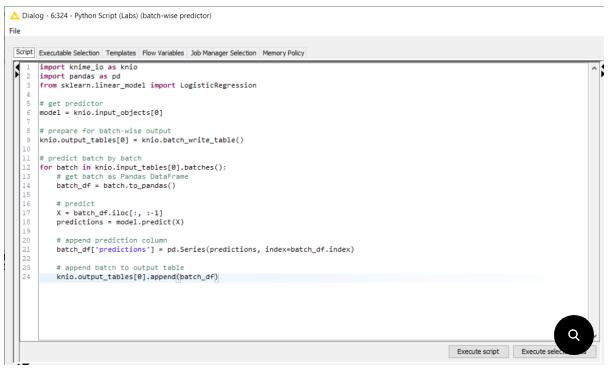
5:批量读取数据并通过附加到 Python Script (Labs) 节点中的输出来存储对这些批次的预测。
移植旧的 Python 脚本
如果您一直在使用先前集成中的 Python Script 节点来开发组件或工作流,您可以通过添加图 6 中所示的代码来简单地调整它们以使用 Python Script (Labs) 节点。

6:将旧脚本移植到 Python 脚本(实验室)节点。
确认 KNIME 和 Python 之间的快速数据传输
在新的 KNIME Python (Labs) 集成中,整个后端已被重写,因此 KNIME 和 Python 之间的数据传输将更快。此外,我们建议使用Columnar Backend 扩展来通过 Python Script (Labs) 节点获得很好性能。带有 knime_io 模块的新 API 允许您通过 PyArrow 表访问数据以进行高效的数据转换,并且您可以使用 pandas 数据帧进行机器学习任务。该模块还可以通过批处理有效地处理大于可用 RAM 的数据表。

-
2026-04-13
GMS 10.9 中文版正式发布 — 新增 PFAS 运移模拟与地下水能量(GWE)模块
GMS 10.9 中文版现已发布。本次更新新增 MODFLOW-USG Transport 对 PFAS 运移模拟的支持、MODFLOW 6 地下水能量(GWE)模型、UGrid 多项改进以及 MODFLOW 6 界面优化等功能,为地下水数值模拟与地热储能分析提供更多工具支持。
查看详情 >
-
2026-03-26
Origin 2026 SR1 服务更新包发布
Origin 2026 服务更新包1现已发布,适用于更新现有Origin或OriginPro 2026 SR0安装或全新安装。本次更新修正了智能填充、Excel公式、分组绘图批量操作及合并图形兼容性等多处问题,并解决了部分崩溃错误。安装后版本号将升级到10.3.0.197,用户可通过“帮助:关于Origin”确认更新完成。
查看详情 >
-
2026-03-10
GTAP数据库 V12已正式发布 - 附视频介绍
GTAP(Global Trade Analysis Project)是一个设立在美国普渡大学农业经济系的经济研究组织。该项目成立于1992年,旨在为贸易政策分析和可计算一般均衡(CGE)建模提供数据支持。全新版GTAP V12已于2026年2月正式发布,欢迎联系北京睿驰科技订购正版GTAP数据库。
查看详情 >

