


使用GAUSS 22了解您的数据
数据整理、清理和探索子啊实证研究中都扮演着不同的角色。数据管理可能很耗时、易出错、并且可能会产生或破坏结果。
GAUSS 22旨在去除处理数据的麻烦,在这篇文章中,我们将介绍怎样子啊建模或估计之前有效地准备和探索真实的数据,我们将看看:
-
加载数据中
-
清理数据以去除错误输入、缺失值等。
-
探索数据
在整个文章中,我们将使用Kaggle上提供的Kick Starter 2018数据。
一、加载数据中
让我们开始在“数据导入”窗口中打开我们的数据。这可以通过两种方式完成:
-
从GAUSS主菜单中选择文件 > 导入数据。
-
在“项目文件夹”窗口中双击文件名。
 数据预览准确地向我们展示了数据将怎样加载,并且对于在我们呢加载数据之前识别数据问题很有用。
数据预览准确地向我们展示了数据将怎样加载,并且对于在我们呢加载数据之前识别数据问题很有用。
我们可以从数据预览中看出:
我们的数据有不应加载的附加标头。
有以外的符号或不可接受的字符。
缺少观察。
数据正在加载为我们想要的类型。
礼物,我们的Kickstarter数据的数据预览中,我们可以看到GAUSS正在检测预览中,我们可以看到GAUSS正在检测变量Category是一个字符号。在下一节中,我们将了解怎样将其改为分类变量。
在数据导入窗口中管理数据
 让我们看看怎样使用mport Windows完成初步的数据清理。具体来说,我们将:
让我们看看怎样使用mport Windows完成初步的数据清理。具体来说,我们将:
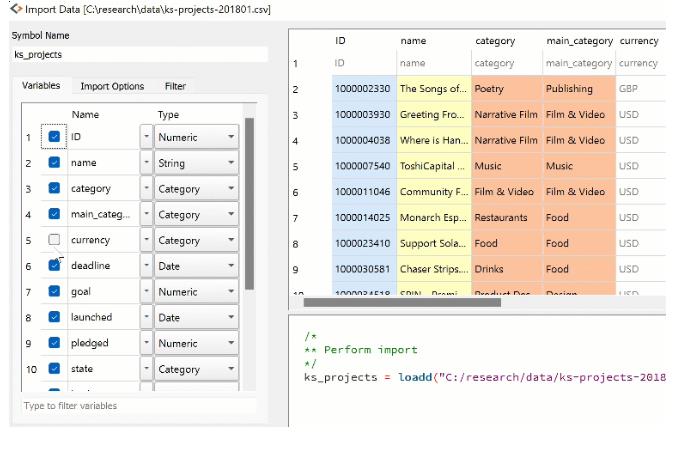
1、更改数据框名称更方便地引用。对于Kickstarter数据,默认符号名称是ks_projects_201801.让我们将其更改为更简单的名称ks_projects,使用符号名称的名称。
2、Cetagory将变量类型从String更改为Category。使用变量列表中的类型下拉菜单更改变量类型。如有必要,可以使用Modify Column Mapping对话框更改分类映射。
3、从导入列表中删除不需要的变量以避免工作空间混乱。元素数据集通常包含我们不需要的多余变量。我们的Kickstarter 数据包含当地货币和真实美元的筹款承诺
我们可以取消选择变量pledged,以及currency from Variables。
4、过滤数据以构建适当的模型
数据集通常还包含我们不想包含在模型中的过多观察结果。“过滤器”选项卡式删除观察值的一种快速渐变的方法。让我们过滤我们的数据以删除全部发布日期早于"2015"的观察结果。

在执行初步数据清理步骤后,我们单击导入以加载我们的数据。
可重用的自动生成代码
数据导入工具的功能之一是它为我们使用数据导入工具执行的全部步骤自动生成代码。

自动生成的代码在导入后打印到命令窗口并列在命令历史记录中。它可以复制和粘贴以备后用。
二、清理我们的数据
现在我们已经加载了我们的数据,让我们更好地了解我们的数据。将对常见数据问题进行一些快速检查,例如:
重复观察
缺失值
数据错误
查看数据
让我们在符号编辑器中打开我们的ks_projects数据以确认它正确加载。

检查重复数据
加载数据后,采取的是检查重复数据,重复数据会扭曲结果,应在建模前去除。
GAUSS包括在GAUSS 22中引入的三个函数,用于处理重复数据:
 作为初步检查,让我们看看数据是否有重复的ID观察结果。
作为初步检查,让我们看看数据是否有重复的ID观察结果。

isunique程序返回1.0000000告诉我们我们的数据是单一的。
三、检查错误输入和拼写错误
分类和字符串数据存在拼写、缩写等错误的机会。有时很难在数据中找到这些错误。
该frequency过程是检查分类变量质量的好方法。让我们来看下country变量的频率报告。


在这个列表中我们看到一个奇怪的类别,N,0". 但是,鉴于此类别的频率。这不在可能是错误输入,可能不想删除此标签,不过,从标签中删除非标准字符是合理的:
 现在,检查我们的频率,我们会看到更新后的country标签:
现在,检查我们的频率,我们会看到更新后的country标签:

生成新变量
GAUSS数据框可以很简单地使用现有变量创建新变量,即框可以很简单地使用现有变量创建新变量。
假设我们对活动启动和截止日期之间的时间量对承诺的影活动启动和截止日期之间的时间量对承诺的影时间量的变量。
GAUSS日期处理和变量名引用使创建变量变得简单。

需要注意的一点是,我们的新变量total_days是标准 GAUSS 矩阵,而不是数据框。我们可以使用该asDF过程转换total_days为 GAUSS 数据帧并添加变量名称。
让我们这样做并将新变量连接到我们的原始数据:

当我们ks_projects在符号编辑器中打开时,我们现在可以看到我们的新变量Total Time及其类型在变量列表中列出。
了解我们的数据
现在我们已经执行了一些初步的数据清理步骤,是时候通过一些简单的数据探索来更好地了解我们的数据了。
汇总统计
快速汇总统计数据使我们能够深入了解我们的数据,并有助于发现异常值和其他数据异常。
该dstatmt过程允许我们在一行中计算描述性统计数据。它计算以下统计数据:
-
Mean
-
Standard deviation
-
Variance
-
Minimum
-
Maximum
-
Valid cases
-
Missing cases
办理手续有几点需要注意dstatmt:
计算字符串变量的有效和缺失观测值。
不计算分类变量的Mean、Std Dev和Variance 。但是,较小和较大观察值是根据基础键值计算的。
让我们看一下我们ks_projects数据的汇总统计信息:
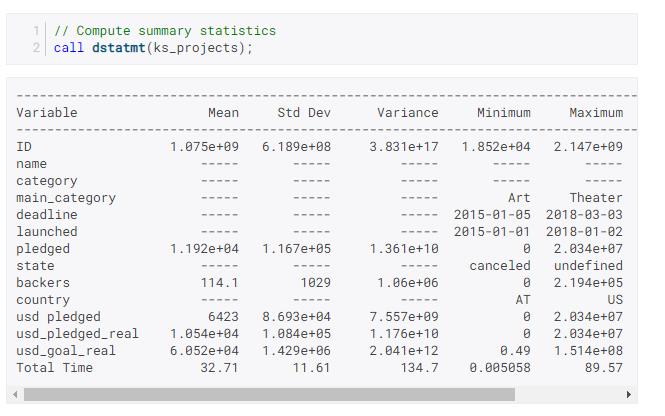
从这些描述性统计数据中脱颖而出的一件事是有很多缺失的观察结果usd_pledged。
一种解决方案是使用usd_pledged_real和删除usd_pledged_variableusingdelcols过程

分组统计
现在,让我们看看变量的平均值如何使用该过程在变量中usd_pledged_real变化。main_categoryaggregate

这很有用,我们可以看到不同项目类别的平均认捐金额存在明显差异。但是,如果我们使用以下方法对结果进行排序,可能会更简单看到这些差异sortc:
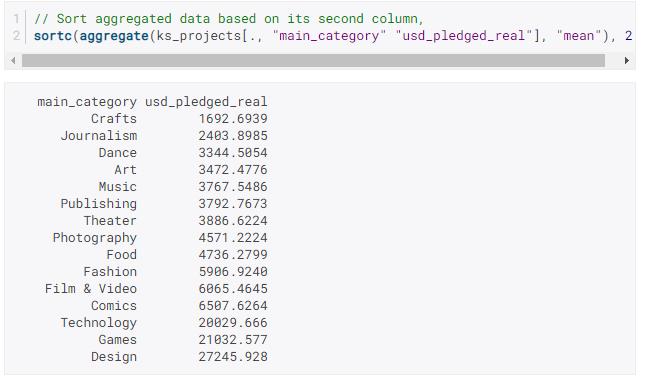
现在我们可以清楚地看到, Craft项目的平均承诺金额低,而Design项目的平均承诺金额。
用可视化探索我们的数据
数据可视化是初步数据探索工具之一。他们可以帮助我们:
-
识别数据中的异常值和异常值。
-
找出变量之间的关系。
-
识别时间序列动态。
-
这些都提供了有助于指导建模的见解。
与出版物图形不同,用于探索的初步数据可视化不需要太多自定义格式和注释。相反,我们可以快速清晰地绘制图表。
在 GAUSS 22 中,绘图通过智能图形属性得到增强,使数据可视化变得更加简单和有用,包括:
-
使用方便的公式字符串指定要按名称绘制的变量的能力。
-
自动使用变量名称和类别标签。
-
by使用 new关键字进行数据拆分。
例如,让我们看看usd_pledged_real与Total Time我们使用散点图创建的变量的关系:
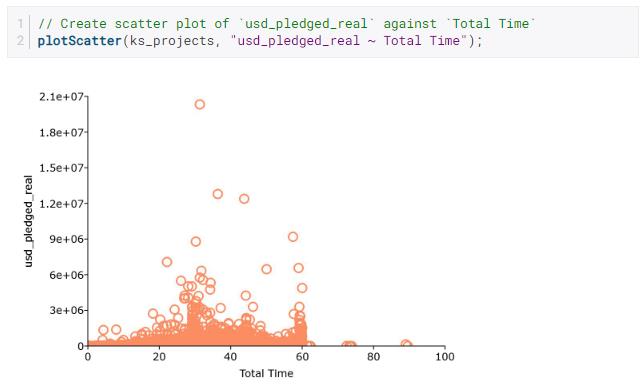
我们的图表提供了一些快速的数据洞察:
-
大多数广告系列的长度在 0-60 天之间。
-
似乎有大约 30、45 和 60 天长度的活动集群。
-
竞选时长和承诺的美元之间似乎没有太大的相关性。
-
大多数活动的收入低于 3e+06,并且有很多活动没有收到承诺。
根据观察,它可能有用:
1、过滤掉没有得到保证的观察(我们不会在这里讨论截断数据的主题,我并不是说这通常是一个很好的建模步骤)

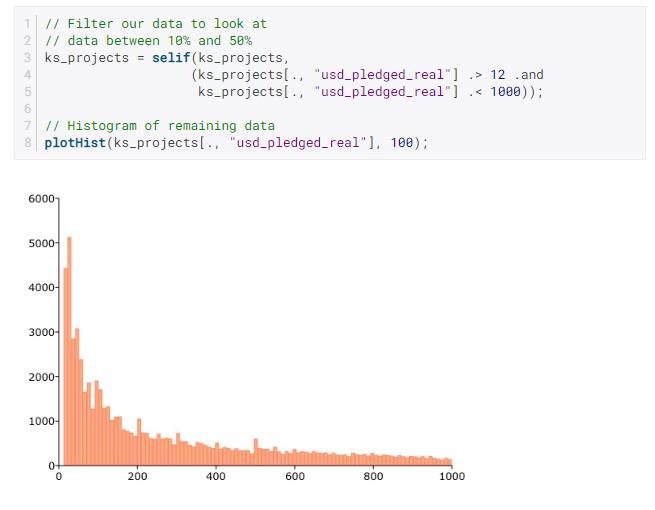
usd_pledged_real使用以下quantile过程查看百分位数:

这很有帮助,它告诉我们 50% 的usd_pledged_real观察值低于约 1,000 美元,80% 低于约 10,000 美元,90% 低于约 19,000 美元。
鉴于这些观察结果,让我们看一下介于 10% 和 50% 之间的承诺的直方图:

-
2026-04-13
GMS 10.9 中文版正式发布 — 新增 PFAS 运移模拟与地下水能量(GWE)模块
GMS 10.9 中文版现已发布。本次更新新增 MODFLOW-USG Transport 对 PFAS 运移模拟的支持、MODFLOW 6 地下水能量(GWE)模型、UGrid 多项改进以及 MODFLOW 6 界面优化等功能,为地下水数值模拟与地热储能分析提供更多工具支持。
查看详情 >
-
2026-03-26
Origin 2026 SR1 服务更新包发布
Origin 2026 服务更新包1现已发布,适用于更新现有Origin或OriginPro 2026 SR0安装或全新安装。本次更新修正了智能填充、Excel公式、分组绘图批量操作及合并图形兼容性等多处问题,并解决了部分崩溃错误。安装后版本号将升级到10.3.0.197,用户可通过“帮助:关于Origin”确认更新完成。
查看详情 >
-
2026-03-10
GTAP数据库 V12已正式发布 - 附视频介绍
GTAP(Global Trade Analysis Project)是一个设立在美国普渡大学农业经济系的经济研究组织。该项目成立于1992年,旨在为贸易政策分析和可计算一般均衡(CGE)建模提供数据支持。全新版GTAP V12已于2026年2月正式发布,欢迎联系北京睿驰科技订购正版GTAP数据库。
查看详情 >

