


生物统计分析软件GraphPad Prism 9已正式发布
生物统计分析软件GraphPad Prism 9已正式发布!Prism 9将您的分析和图形扩展到维度。

维度数据
Prism 9对多变量数据进行了改进。使用标准结构数据集:
-
增加的数据:限制在数据表中1024列以下的数据
-
自动识别变量类型:将多变量数据表中的变量识别为连续值,分类或标签值
-
数据表中的文本信息:以文本形式输入数据。不用编码“0”和“1”之类的变量,在数据表中输入“Male”和“Female”
-
自动变量编码:输入您的数据,让Prism负责其余的工作。Prism会自动将分类文本变量编码为数字“虚拟”变量
在研究中,我们会发现自己拥有关实验中不同变量的信息。举例,想象下在给个体服用降低血压的实验药物或安慰剂后测量他们的血压,除了记录的血压测量值之外,您还记录了有关受试者的年龄,身高,体重,性别,种族以及潜在变量的信息。
设计统计技术来分析这类“多变量”数据,例如,多元线性回归和多元逻辑回归。使用这些类型的“多个变量”分析您可以探索感兴趣的结果。为了改进数据信息密度,Prism提供了多变量数据表以将数据放在标准数据结构中,该数据结构被统计软件使用并打包在,如,SPSS和MATLAB)。在这种格式下,每列代表不同的变量,而每行代表不同的主题(主题的变量测量值将放入该主题所在行的相应列中)。
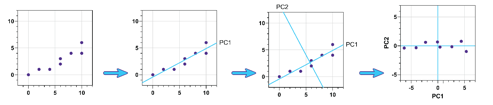
注意:上图以二维形式显示了PCA的可视示例。Prism中的PCA可以对变量执行!
主成分分析(PCA)
收集的变量数量可供研究的学科数量。考虑基因表达研究,分为两组的受试者中测量了成百上千不同基因的表达水平:治疗组和对照组。可能是变量太多而无法使模型适合数据。但是,选择一些要从分析中排除的变量删减可能有用的信息!PCA是一种“降维”技术,可用于减少变量的数量,同时从数据中尽可能减少信息。
PCA功能:
通过平行分析(Kaiser方法,总方差阈值方法等)选择组件
碎石图,分数图和双线图的生成
自动PCA结果,以用于多元线性回归(主成分回归)
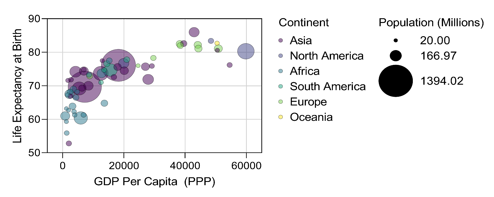
向图形添加新尺寸
从原始数据,符号位置(X和Y坐标),大小和填充颜色的编码变量创建气泡图。请注意,可以使用分类(分组)或连续变量来定义符号颜色和符号大小。
在此图上,有地区显示为单个圆圈。圆圈的X坐标代表该图的GDP(PPP),而Y坐标代表出生时的平均预期寿命。符号的大小与其所代表的的人口成比例。符号的颜色代表该所在的大陆。在这种情况下,变量(颜色)是分类变量,但气泡图中的颜色也可以由连续变量定义。
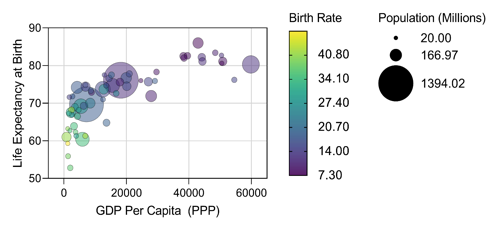
在该图中,符号的X坐标,Y坐标和大小与以前相同。但是,现在该符号的颜色以连续比例表示该每1000个人的出生率。Prism现在还具有内置的半透明配色方案,以便可以看到重叠的符号。
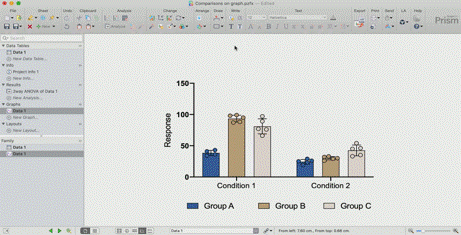
自动将结果添加到图形
执行分析即可。然后单击以将这些结果自动添加到图形中。要自定义这些行和星号,需再次单击工具栏按钮。调整数据或分析,图形上显示的结果将自动更新。但是请记住,P值只是部分。别忘了报告估算值(例如,均值差异为95%置信区间!)。
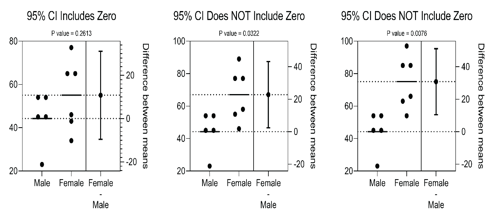
使用估计图可视化T测试结果
在测试中执行,Prism现在将自动创建结果的估计图。在此图上,两组的原始数据都将绘制在左侧的Y轴上。在右边的Y轴上,将绘制组均值的差及其95%CI置信区间。该可视化提供的信息少。
新的功能
-
主成分分析(PCA),通过新维度的方差将高维空间中的数据投影到低维空间中的方法。PCA主要用作探索性数据分析和建立预测性模型的工具。它通常用于可视化群体之间的遗传距离的相关性。
-
PCA生成的新图形类型
-
Scree图:Scree图用于显示主成分分析(PCA)中标识的主成分(PC)的原始属性值
-
Score plots:Score plots提供了种在两个指示的PC(将PC1作为水平轴,将PC2作为垂直轴)的新(缩小)维空间中查看原始数据的方法。
-
Loading plots:Loading plots提供了种可视化两个选定主成分系数的方法
-
Biplots:Biplots是Score plots和loading plots的组合
-
方差图的比例
-
多变量图 以多变量数据表中的数据位图
-
制作气泡图,其中符号大小由数字或分类变量编码
-
使用变量编码符号颜色和连接线的外观
-
选择外观经过改进的“格式图”对话框上进
气泡图的新半透明配色方案
估算图,这是种直观的方式来表示两个样本的测试(例如t检验)的结果。该图原始数据以及分析结果摘要的目的是效应大小和置信区间概念。
图形上的成对数据,这是可视化的自动生成,该可视化将用户数据与假设检验期间进行的成对数据的结果相结合(即,将有意义的星标自动添加到图形中)。
功能改进
-
非线性回归
-
用户定义方程式评估的性能
-
参数为微分方程定义X0
-
创建五个残查图(如,新的Actual vs Predicted图)。以前,分析可生成一张图
-
重新排列并重新标记了“NLR参数”对话框的“置信度”选项卡上“参数和拟合”部分的选项
-
多元线性/逻辑回归
-
选择具有自动参考规范的分类自变量的模型
-
指定基于数据的“自动”参考规范的方法
-
通过MLR参数对话框的“参考”选项卡中的“定义类别顺序”选项,指定分类变量结果的顺序
-
改进的模型控制(树形视图),可以表示分类变量和交互
-
对话框中的模型表示
-
使用数据表中的数据或参数对话框中预测变量的值结果(因变量)的值进行插值(用于多个线性回归)
-
改进的相关矩阵输出,因此可以生成结果的热图
-
多重两个样本测试分析(多重t检验分析):
-
具有Welch校正的多个未配对t检验
-
多重配对t检验
-
多重比率配对t检验
-
多个非参数不成对的Mann-Whitney检验
-
多个非参数配对的Wilcoxon检验
-
多个非参数非配对Kolmogorov-Smirnov检验
-
统计分析
-
允许计算具有自定义置信区间水平的均值
-
允许计算具有“无错误”,“四分位数”,“max/min”,“百分位数”的中位数
-
允许计算具有“无误差”,“几何SD”,“CI”的几何平均数
-
双向方差分析:效果模型
-
在双向ANOVA中对主要效果模型(无相互作用项)进行重复数据处理
-
主要效果模型,允许在双向ANOVA中组合缺失因子水平
-
对于未经复制的双向方差分析,不允许进行“效果”多重比较
-
使用分析常量名称而不是值来生成带有链接参数的标准转换的默认标题
-
在“参数:非线性回归”对话框的“置信度”选项卡中将默认值更改为不稳定选项
-
更新了可对多变量表执行的分析行为,以处理不同的变量选项
-
创建相关矩阵时,选择忽略缺少或排除值的行。选择此选项后,矩阵中的相关系数均从同一组行计算得出
-
允许“选择和转换”分析在绿色多变量结果 表中定义变量的类型
-
(Mac)添加了警报“您正在尝试分析单个列。如果要执行单样本t检验,请使用个样本t和Wilcoxon测试分析。t检验需要两组(均在Y列中;X列将被忽略)”
-
非数学功能改进
-
新数据限制
-
改进了1024个数据集[字母A...AMJ]和512个子列的数据表限制
-
提升了图形限制,可以绘制1024个数据集
-
多个可变数据表
-
在Prism的多变量数据表中定义变量类型的功能
-
在Prism的多变量数据表中定义量类型的功能
-
符号和Unicode
-
在“插入”主菜单中添加了“字符>Unicode符号...”命令,该命令将打开标准系统的“字符映射”对话框,并允许输入符号
-
(Windows)Prism的“插入字符对话框”,并用与Unicode兼容的字符替换了将Symbols字体用于希腊语/数学/欧洲字符的旧方法,从而实现了跨平台的第三方应用程序的兼容性。
-
右键单击图纸类型(图形和布局)时,将“导出”命令添加到在导航器中打开的上下文菜单中。
-
如果删除生成这些图形的父分析,Made Prism也会删除图形,但是当分析将曲线添加到现有数据图形时,Made Prism不会删除图形。
-
在主“更改-配色方案”和“更改颜色”工具栏的下拉菜单中添加了具有半透明配色方案的新部分。
-
数据表和结果中图形或图形上数据点的格式
-
(Windows)使用数据表中的“格式化点”上下文菜单,可以将条形图,误差条和线选项应用于带有条形图的散点图
-
(Windows)可以使用数据表中的“格式点”上下文菜单来应用“误差线”和“线”选项,以散布成组的图形
-
(Windows)可以使用“格式化点”上下文菜单将数据表中的“行”和“四分位数”格式应用于小提琴图
-
(Windows)可以使用数据表中用于叠加散点图的“格式点”上下文菜单来应用“误差线和线”选项
-
(Windows)可以格式化绿色结果表中图形上的数据点。案例1056514
-
(Windows)从数据表的“格式点”上下文菜单启用了小提琴图上所选符号的格式
-
(Windows)在“Violin plot only”图中启用了小提琴的格式设置上下文菜单,方向相反
-
(Mac)启用了“格式化点”上下文菜单中的“线”部分,以便能够使用数据表中的均值和中值来格式化图形上的数据
-
在“欢迎”对话框中,示例数据文件的浮动注释中的URL已更新,以指向Prism 9用户指南(而不是早期版本的指南)
-
(Windows)Prism现在可以将Excel中的“True”或“False”布尔值分别作为“1”和“0”导入Prism的多变量数据表中
-
(Windows)Made Prism在系列导航器面板中打开的“删除工作表”对话框中显示该系列的工作表
-
(Windows)将系统要求更新为Windows7。添加了在Prism在Vista上启动时更新Windows的警报
-
(Mac)删除了“列”/“分组”/“偶发性”/“多个变量”/“数据”表中单独列顶部的“Y”标签
-
(Mac)Prism会记住上一次使用的窗口的大小,并将其用作新窗口的默认大小
-
(Mac)启用了“整个图的一部分”的“更改”和上下文菜单中将“反向数据设置顺序”命令重命名为“反向类别顺序”
性能改进
-
将“相关矩阵”分析的性能提高了20倍以上
-
(Windows)使用残差计算将拟合样条线/LOWESS分析的性能提高了约10倍
-
(Windows)将“逻辑回归”分析的性能提高了1.5倍以上
-
(Windows)将“转换”分析的性能提高了约4倍
-
(Windows)将“修剪行”分析的性能提高了约3倍
-
(Windows)改进了模拟具有大量值的XY数据的性能,并且多次复制的速度超过10倍
-
(Windows)改进了当源数据多于3x的行时切换到分组图形表的性能
-
(Windows)改进了“规范化”分析的性能
-
(Windows)当源数据表多次分析链接的数据时,改进了“蒙特卡洛”分析的性能
-
(Mac)将“转换”分析的性能提高了约2.5倍
-
(Mac)将“修剪行”分析的性能提高了10倍以上
-
(Mac)改进了当源数据多于2x的行时切换到分组图形表的性能
-
(Mac)将“规范化”分析的性能提高了5倍以上
基础设施
-
(Windows)Prism 9用于64位Windows。没有Windows的32位的Prism
-
(Mac)Prism 9需要macOS 10.12(Sierra)或以上版本

-
2026-04-13
GMS 10.9 中文版正式发布 — 新增 PFAS 运移模拟与地下水能量(GWE)模块
GMS 10.9 中文版现已发布。本次更新新增 MODFLOW-USG Transport 对 PFAS 运移模拟的支持、MODFLOW 6 地下水能量(GWE)模型、UGrid 多项改进以及 MODFLOW 6 界面优化等功能,为地下水数值模拟与地热储能分析提供更多工具支持。
查看详情 >
-
2026-03-26
Origin 2026 SR1 服务更新包发布
Origin 2026 服务更新包1现已发布,适用于更新现有Origin或OriginPro 2026 SR0安装或全新安装。本次更新修正了智能填充、Excel公式、分组绘图批量操作及合并图形兼容性等多处问题,并解决了部分崩溃错误。安装后版本号将升级到10.3.0.197,用户可通过“帮助:关于Origin”确认更新完成。
查看详情 >
-
2026-03-10
GTAP数据库 V12已正式发布 - 附视频介绍
GTAP(Global Trade Analysis Project)是一个设立在美国普渡大学农业经济系的经济研究组织。该项目成立于1992年,旨在为贸易政策分析和可计算一般均衡(CGE)建模提供数据支持。全新版GTAP V12已于2026年2月正式发布,欢迎联系北京睿驰科技订购正版GTAP数据库。
查看详情 >

