



WordStat-文本分析软件
WordStat是一款易于使用的文本分析软件 - 不管您是需要文本挖掘工具来提取主题和趋势,还是使用新的定量内容分析工具进行仔细和测量。需要快速从大量文档中提取和分析信息的人都可以使用WordStat。此内容分析和文本挖掘软件可用于很多应用程序,例如开放式响应分析,商业智能,新闻报道的内容分析等。WordStat与SimStat统计数据分析工具-QDA Miner定性数据分析软件与Stata-StataCorp的综合统计软件为您提供了便捷,可以分析文本并将其内容与结构化信息(数字和分类数据)相关联。
使用文本挖掘浏览文档内容
-
使用WordStat分析大量非结构化信息。该软件每分钟可处理2500万个单词,使用聚类,多维缩放,邻近图等功能提取主题并自动识别模式。
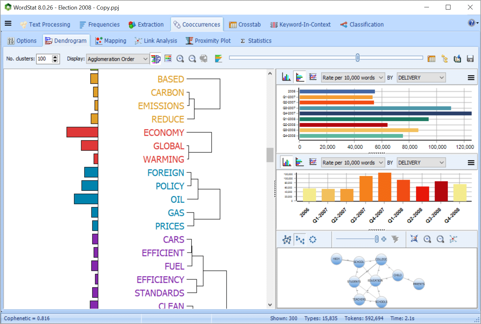
使用浏览器模式提取含义
-
使用资源管理器模式快速的从大量文本数据中提取含义,尤其是对那些文本挖掘经验很少的人,只需单击一下,就可以提取文档中常用的单词,短语和突出的主题。

从多种来源进口
-
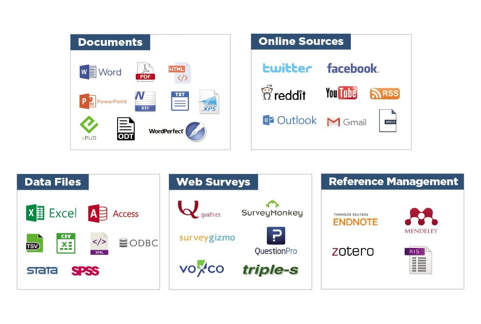
导入Word,Excel,HTML,XML,SPSS,Stata,NVivo,PDF和图像。连接并直接从社交媒体,电子邮件,网络调查平台和参考管理工具导入。
使用主题建模提取主题
-
使用基于单词,短语和相关单词(拼写错误)的新自动主题提取功能,浏览大型的文本集中的主题。

探索联系
-
探索单词概念之间的关系,并检索与特定连接关联的文本段。
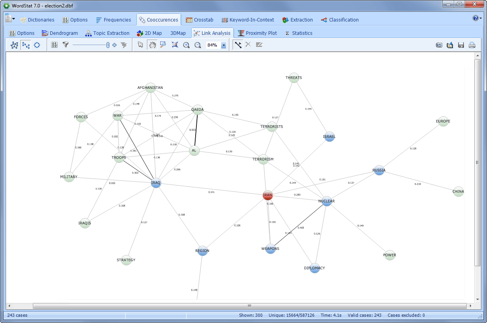
将文本与结构化数据相关联
-
探索非结构化文本与结构化数据(例如日期,数字或分类数据)之间的关系,以识别子组之间的时间趋势或差异,或使用统计和图形工具(对应分析,热图,气泡图等)。

使用字典分类您的文本数据
-
使用现有词典实现分析自动化,或使用单词,短语,接近规则等创建您自已的分类模型。
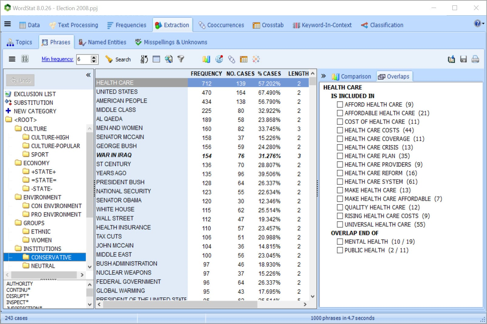
为词典获得帮助
-
使用提取常用短语和技术术语并在文本集合中识别拼写错误,同义词,反义词和相关单词的工具,更快的构建词典。
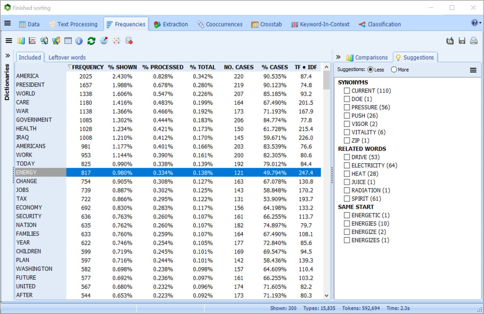
使用机器学习分类您的文本数据
-
使用Naïve Bayes和K-Nearest Neighbours来开发和改进自动文档分类模型。

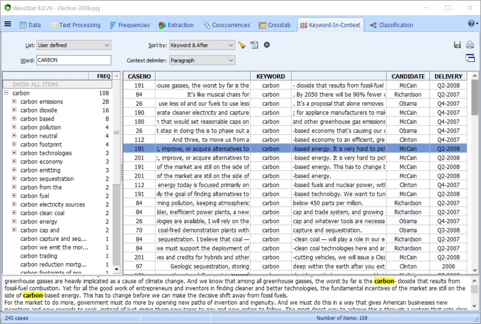
一键单击返回源文件
-
通过从功能,图表或图形返回到文本来验证或深入分析。您可以使用“关键词检索”或“上下文中的关键字”功能来检索句子,段落或整个文档。这在建立分类法或词义歧义时很有用。您还可以将QDA Miner代码附加到检索到的段。
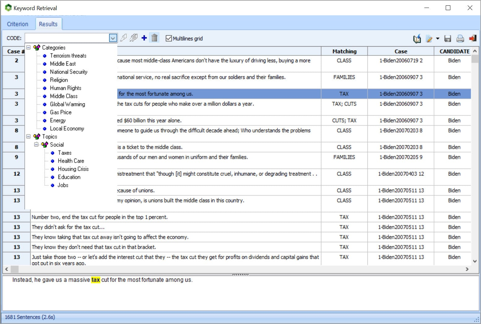
执行定性编码
-
将WordStat与新的定性编码工具(QDA Miner)结合使用,以便在需要时更准确的探索数据或更深入的分析文档或提取的文本段。
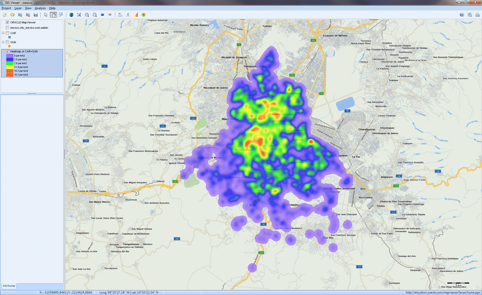
将非结构化文本转换为交互式地图(GIS映射)
-
将非结构化文本数据与地理信息相关联,并创建数据点,图和热点图的交互式图表,以及用于将位置名称,邮政编码和IP地址转换为维度和经度的地理编码Web服务。
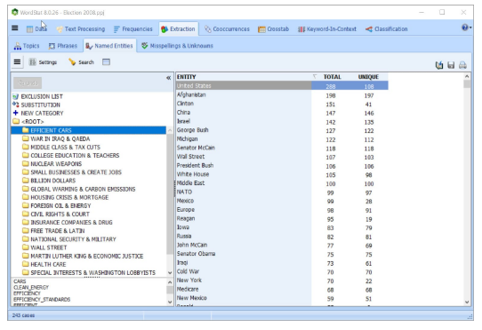
自动提取命名实体
-
自动提取命名的实体,可以使用方便的拖放操作将其添加到分类字典中。
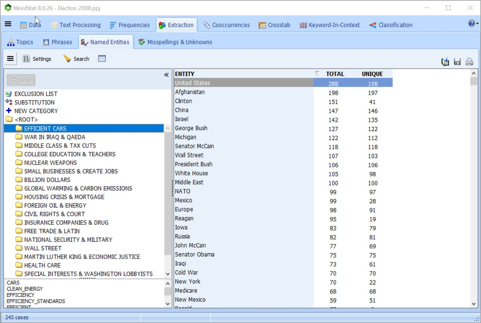
导出结果
-
将文本分析结果导出为常见的行业文件格式,例如Excel,SPSS,ASCII,HTML,XML,MS,Word和图形(例如PNG,BMP和JPEG)。
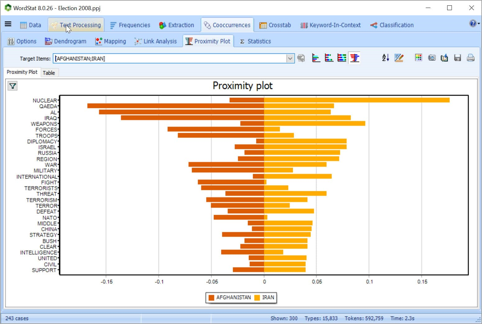
使用PYTHON脚本转换文本
-
使用Python脚本及其开放源代码库预处理或转换文本文档,以便在WordStat中进行分析。
特点:
使用WordStat,数据分析师可以从大量文档中提取有价值的文本分析结果,例如客户反馈,电子邮件,开放式回复,采访记录,时间报告,法律文档,博客,网站等。以下是WordStat的内容分析和文本挖掘功能列表:
从多个来源导入
WordStat允许您从很多来源直接导入多语言内容:
-
导入文档:Word,PDF,HTML,PowerPoint,RTF,TXT,XPS,ePUB,ODT,WordPerfect。
-
导入数据文件:Excel,CSV,TSV,Access。
-
从统计软件导入:Stata,SPSS
-
从社交媒体导入:Facebook,Twitter,Raddit,YouTube,RSS
-
从电子邮件导入:Outlook,Gmail,MBox
-
从网络调查中导入:Qualtrics,SurveyMonkey,SurveyGizmo,QuestionPro,Voxco,Triple-S
-
从参考管理工具中导入:Endnote,Mendeley,Zotero,RIS
-
导入图形:BMP,WMF,JPG,GIF,PNG。自动提取与这些图像相关的信息,例如地理位置,标题,描述,作者,评论等,并将其转换为变量
-
从XML数据库导入
-
ODBC数据库连接可用
-
从定性软件导入项目:NVivo,Atlas.ti,Qdpx文件
-
导入和分析多语言文档,包括从右到左的语言
-
监视指定文件夹,并自动导入存储在此文件夹中的文档和图像,或监视对原始源文件或联机服务的更改。

整理数据
多种功能使您可以通过使分析过程明了的方式组织数据:
-
分组,标记,排序,添加,删除文档或查找重复项
-
使用文档转换向导手动或自动将变量分配给文档,即:日期,作者或人口统计数据,例如年龄,性别或位置
-
对变量进行重新排序,添加,删除,编辑和重新编码
-
根据变量值过滤大小写
使用资源管理器模式提取含义
使用资源管理器模式可以便捷的从大量文本数据中提取含义,这是为那些文本挖掘经验很少的人设计的。
使用主题建模工具,找出常用的单词,短语并提取文档中的主题。
使用文本挖掘浏览文档内容
在几秒钟内,探索大量非结构化数据的内容并提取有见地的信息:
-
提取常用的单词,短语,表达方式
-
在单词或短语上使用聚类或2D和3D多维缩放提取主题
-
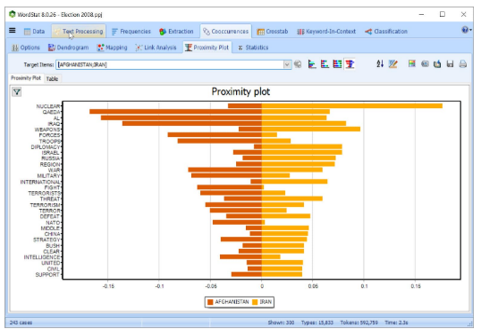
使用邻近图识别与目标关键字同时出现的关键字
-
使用链接分析功能探索单词或概念之间的关系
-
通过应用关键字同时出现条件(在一个案例中,一个句子,一个段落,一个n个单词的窗口,一个用户定义的段)以及聚类方法(一阶和二阶接近度,选择)来微调分析性指标
-
使用分层聚类,多维缩放,链接分析和邻近图来探索概念或文档之间的相似性。
使用主题建模来提取突出的主题
通过将自然语言处理和统计分析(NNMF或因子分析)结合使用,不只对单词而且对短语也能使用的自动主题提取功能,从大型文本集中概览主题和相关单词(包括拼写错误)。
在层析聚类分析中,一个单词可能出现在一个聚类中,主题建模可能会导致单词与多个主题相关联,这一特点更真实的表示了某些单词的多义性以及该单词的多个上下文单词用法。
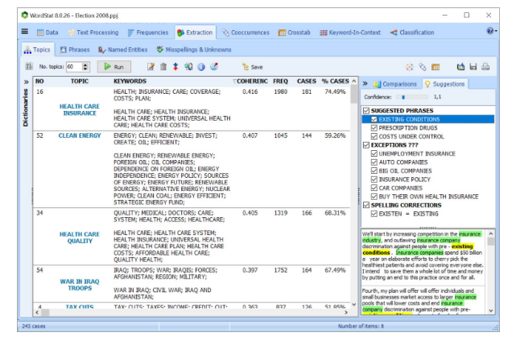
探索联系
使用网络图探索单词或概念之间的联系。使用三种布局类型检测共现的基础模式和结构:多维缩放,基于力的图形和圆形布局。
图形是交互式的,可用于探索关系并检索与连接关联的文本段。
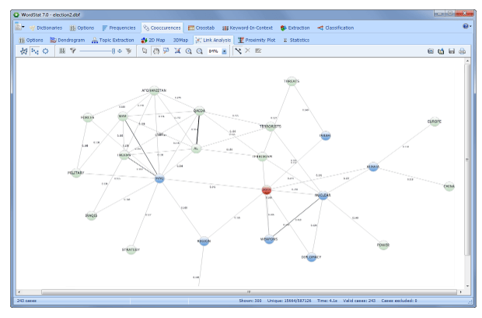
使用文本与结构化数据相关
探索非结构化文本与结构化数据之间的关系:
-
识别时间趋势,子组之间的差异,或使用统计和图形工具(偏差表,对应分析,热图,气泡图等)评估与等级或其他类型或数字数据的关系。
-
使用不同的关联度量的评估单词出现与名义或有序变量之间的关系:卡方,似然比,Tau-a,Tau-b,Tau-c,对称Somer's D,非对称Somers'Dxy和Dyx,Gamma,Person's R,Spearman's
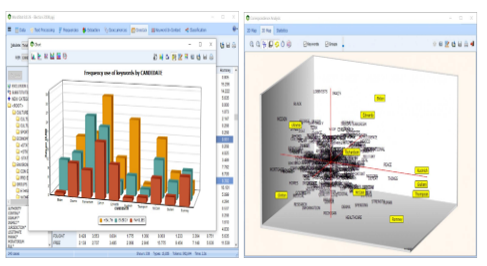
使用字典对文本数据进行分类
使用现有字典实现分子自定化,或者创建您自已的单词和短语分类模型
在字典中,可以实现布尔值(AND,OR,NOT)和接近度规则(NEAR,AFTER,BEFORE),并使用正则表达式公式从文本数据中提取信息。
字典调节的词语修饰和词干可用于多种语言,并且自动单词替换选项使您可以用目标关键字替换多个单词。用户定义的停用词列表可用多种语言提供。以避免出现非必要的常用词(例如他,她,它等)在分析中使用。
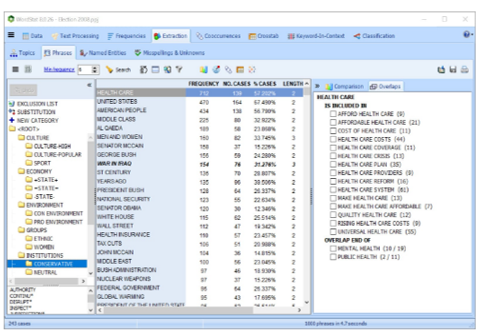
获得词典构建帮助
通过提取常用短语和技术术语以及在文本集合中识别拼写错误和相关单词(同义词,反义词,全名,同义词,上位词,下位词)的工具,获得计算机协助,以建立分类标准。

使用机器学习自动对文本数据进行分类
使用Naïve Bayes和K-Nearest Neighbours开发和优化自动文档分类模型。用户可以选择多种验证方法:leave-but-one,n-fold cross-validation,split sample。实验模块可用于比较预测模型和精细分类模型。
分类模型可以保存到磁盘中,并稍后在QDA Miner中的独立文档分类实用程序,命令行程序或编程库中应用。
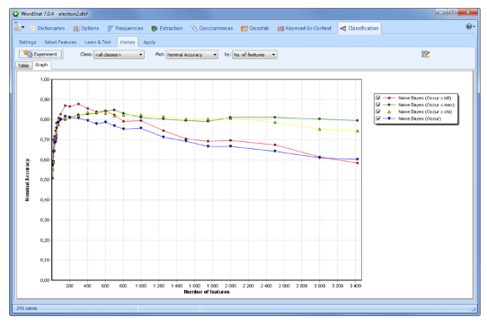
一键返回源文档
通过使用关键字检索或上下文中的关键字来检索句子,段落或整个文档,从功能,图表或图形中返回文本,从而验证或深入分析。这在建立分类法或词义歧义时很有用。
检索到的文本段可以按关键字或自变量排序。您可以将QDA Miner代码附加到检索到的段上,或以表格格式(Excel,CSV等)或文本报告(MS Word,RTF等)将其导出到磁盘。
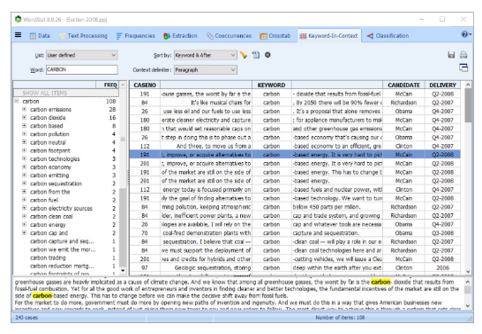
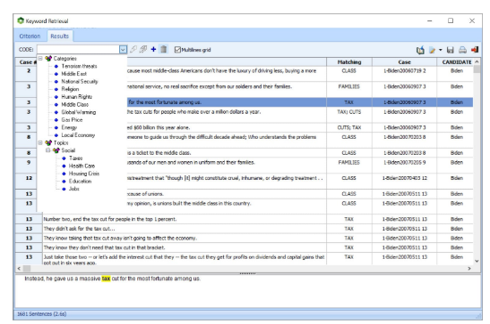
执行定性编码
将WordStat与新的定性编码工具(QDA Miner)结合使用,以便在需要时更准确的浏览数据或更深入的分析指定文档或提取的文本段。
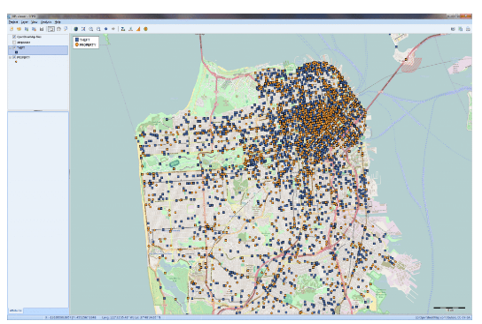
将非结构化文本转换为交互式地图(GIS映射)
将非结构化文本数据与地理信息相关联,并创建数据点,主题地图和热图的交互式图表,以及用于将位置名称,邮政编码和IP地址转换为纬度和经度的地理编码Web服务。
自动提取名称和拼写错误
自动提取命名实体(名称,技术术语,产品和公司名称),可以使用方便的拖放操作将其添加到分类字典中。
拼写错误和未知单词会自动提取出来,并与用户词典中的现有条目匹配,并且可以迅速添加到词典中。
导出结果
将文本分析结果导出为常见的行业文件格式(例如Excel,SPSS,ASCII,HTML,XML,MS Word),以及统计分析工具(例如SPSS和STATA)以及图形(例如PNG,BMP和JPEG)。
使用Python脚本转换文本
使用Python脚本及其开放代码库来预处理或转换文本文档,以便在WordStat中进行分析。
WordStat 2023的新功能:
WordStat 2023的发布,这代表着在将词义消歧应用于主题模型方面向前迈出了重要一步。我们特有的主题丰富功能经历了重大改进,引入了几个新的主题建模功能,以帮助用户从他们的数据中获得更深刻的见解。此外,还实施了多项速度优化,使软件响应速度更快、用户更友好。
1. 改进主题丰富
WordStat现在向提取的主题添加了更多相关短语,同时还为其他短语提供了改进的建议。此外,它现在在识别假阳性表达或异常方面具有更高的准确性,可以将其合并到主题模型中,以帮助减少与提取的主题无关的上下文相关的单词的歧义。
2. 主题建模词云
主题模型表右侧的比较面板现在有一个新添加的词云,直观地描述了所选主题中排名靠前的词的相对重要性。此词云可以自定义、复制到剪贴板或以BMP、PNG或JPEG等标准图形格式保存到磁盘。
3. 新增集成文本检索功能
可以启动主题网格右侧的一个新的方便的示例文本面板,以自动显示与所选主题匹配的句子或段落。这些文本片段按相关性降序排列,主题词以粗体显示,便于理解每个主题的本质并识别可用于说明的关键示例。这个强的工具使用户可以更深入地了解他们的数据,并促进更有效地交流他们的发现。
4. 提高顶部富集速度
由于进行了大量的优化工作,主题丰富过程得到了显着加速,导致性能提高比以前的版本快10到20倍。
5. 瞬时短语提取
利用多核处理的强功能,短语提取现在与主要文本处理无缝集成,使用户几乎可以即时访问结果。例如,在包含超过50,000条客户评论的数据集上,提取常用的5000个短语现在只需0.4秒即可完成,而之前的版本需要14秒。
技术信息
操作系统:Microsoft Windows XP , 2000 , Vista , Windows 7,8和10
内存:从256MB(XP)到1GB(Vista , Windows 7, 8和10)
磁盘空间:40MB


- 2026-07-15
- 2026-07-15
- 2026-07-03
- 2026-06-30
- 2026-06-25
- 2026-06-25

- 2026-07-15
- 2026-07-15
- 2026-07-15
- 2026-07-15
- 2026-07-15
- 2026-07-15










